This blog post will describe the steps I took to modify Google’s Syzkaller in a way that allowed me to fuzz the entirety of FUSE, including its file system operations which was previously not easily possible with Syzkaller.* Before diving into any code changes, I will lay out some of the basics about FUSE, its architecture, Syzkaller’s architecture, and finally discuss why they are not compatible. If you are already familiar with FUSE and/or Syzkaller, feel free to skip the ‘Fuzzing FUSE‘ section where I begin describing this fuzzer’s design.
*Before I start with the blog post I want to mention that I was working on this project in August, at the same time Google was working on fuzzing FUSE as well. I did not know this and for this reason, my approach differs in a lot of aspects. In fact, I rewrote Syzkaller for the purpose of fuzzing FUSE so much that it was no longer compatible with the main branch.
FUSE explained
Linux kernel FS drivers basics
FUSE stands for Filesystem in User-space. It is a feature that allows even unprivileged users to implement and mount their own, logical file system implementations. In order to understand what this actually means and which security boundaries are in place, let’s go into what roughly happens when a user-space program interacts with any physical file backed by some sort of filesystem and then compare it to what happens when the same program interacts with a file that is backed by a filesystem in user-space.
Whenever a user-space program wants to interact with a file, it needs to obtain a file descriptor for that file. To do so, the open() system call is executed with 3 arguments:
- The path of the file to be opened
- Flags describing how the file should be opened (e.g. as read-only, create the file if it does not exist)
- In case the file should be created if it does not exist, the permission bits of the new file.
The kernel then internally resolves the path of the file and finds out which filesystem driver is responsible for managing this specific file (or directory or symbolic-link or anything else for that matter). Each filesystem driver registers a couple of structs to the kernel at load-time, most importantly for our sake: struct inode_operations and struct file_operations. These structures contain function pointers the kernel will use to perform file-system related operations such as writing to a file or checking if a file exists at all. The kernel uses these structs to construct a struct file for the requested file. If everything went well, the kernel returns a file descriptor. A file descriptor (FD) is simply an index passed as an argument to file-related system calls which the kernel can use to lookup a pointer to the just created struct file within the process’ files table and then act on it.
Let’s assume a user-space program successfully opened a file and obtained a valid file descriptor and now wants to write to this file. In order to do so, it will call the write() system call with the following arguments:
- the file descriptor that was obtained from the call to
open() - a pointer to a buffer of bytes that should be written to the file
- the number of bytes that should be written
The kernel then simply resolves the file descriptor to the struct file that was created earlier, makes some general checks, and then calls the write() function pointer of the driver responsible for this file. This flow of execution is roughly the same for all file-related system calls of the Linux kernel and is the reason the kernel does not need to implement new syscalls for each file operation for each file system. This abstraction can also be illustrated by this graphic:

write() call backed by a FS driver in the Linux kernel
In conclusion: a file-system driver usually runs within the kernel context and can access exported kernel symbols. To put it (overly) simple, a file-system driver just exports some structs containing function pointers that the kernel can call when needed. The kernel does not need to know anything about the internal workings of the driver, it just needs to know that the driver can be accessed through a defined interface.
FUSE basics
Now that we discussed very abstractly how a file-system driver works, let’s go into how these concepts apply to the FUSE driver.
It makes sense to first make a detour and explore how an unprivileged user-space process can mount and implement a filesystem in user-space. This will help us better understand the execution flow in the kernel for a file operation on a FUSE backed file.
There are no system calls related to FUSE. The FUSE driver follows the same rules as every other file-system driver and thus a user needs to mount() a file-system in user-space. However, mounting is a privileged operation. For this reason, Linux distributions which enable the FUSE feature ship with a SUID-set binary called fusermount, which handles the mount() system call.
Before the mount() syscall is actually executed, one step has to be taken which is unique to FUSE. The process that wants to implement a file-system in user-space needs to obtain an FD for the /dev/fuse character device. This file descriptor must then be set as one of the mounting options of the final FUSE mount and is passed to fusermount. An example of a mount() syscall made by fusermount then looks like this:
mount("fuse", "/tmp/fuse-example", "fuse.fuse", MS_NOSUID|MS_NODEV, "fd=3,rootmode=40000,user_id=1000,group_id=1000");
Please notice the fd=3 mount option. Internally, the FUSE driver will then associate this particular mount with the file represented by this file descriptor.
Now that we know that a process wanting to create a FUSE mount needs to open and associate a /dev/fuse file with this mount, let’s look at how the execution flow of a file-operation on a FUSE backed file could look like:

write() call on a file handled by the FUSE driver.
When you compare this image with the first graph showing the execution flow of a file-operation on a non-FUSE file-system, you will notice that an extra step is made. First, a user-space program issues a request for the operation. Then the kernel gets the corresponding function pointer of the FUSE driver for the issued request and calls into the FUSE driver.
The actual implementation of the FUSE driver for, in this case, let’s say a write(), is actually generic. All it does is create a FUSE request for this file operation. The user-space program that implements the mount of the file that should be written to can then read() this FUSE request through the file descriptor obtained by /dev/fuse and can also write() a FUSE reply back. The FUSE driver then interprets the FUSE reply and returns an appropriate result to the kernel and thus the userspace-program which issued the write() operation in the first place.
We will now look at how this FUSE protocol roughly works.
The FUSE protocol
Every time a process issues a file-system related operation on a file which is backed by a FUSE driver, a FUSE request is generated and read by the FUSE server handling this request. The server then replies with a FUSE reply. In this section, we will look at the basics of this protocol in order to better understand the implementation of a fuzzer for this protocol.
Every FUSE request begins with the same header, struct fuse_in_header:
struct fuse_in_header {
uint32_t len; /* Total length of the data,
including this header */
uint32_t opcode; /* The kind of operation (see below) */
uint64_t unique; /* A unique identifier for this request */
uint64_t nodeid; /* ID of the filesystem object
being operated on */
uint32_t uid; /* UID of the requesting process */
uint32_t gid; /* GID of the requesting process */
uint32_t pid; /* PID of the requesting process */
uint32_t padding;
};
Here are the 3 most important fields in order to understand this protocol:
- opcode: The type of file operation that should be performed
- unique: A unique 64bit identifier for this request generated by the FUSE driver. When replying to this request, this identifier must be set in the reply.
- nodeid: A unique 64bit identifier for the inode this operation acts on
At the time of writing, there are 49 FUSE opcodes defined. The definition of these is simply an enum:
enum fuse_opcode {
FUSE_LOOKUP = 1,
FUSE_FORGET = 2,
FUSE_GETATTR = 3,
FUSE_SETATTR = 4,
FUSE_READLINK = 5,
FUSE_SYMLINK = 6,
FUSE_MKNOD = 8,
FUSE_MKDIR = 9,
FUSE_UNLINK = 10,
FUSE_RMDIR = 11,
FUSE_RENAME = 12,
FUSE_LINK = 13,
FUSE_OPEN = 14,
FUSE_READ = 15,
FUSE_WRITE = 16,
...
Let’s go through an example of what the execution flow would be in most cases if a FUSE_LOOKUP request was issued.
- A lookup occurs before e.g.
open()can be called. This function is called by the kernel when trying to figure out if an inode exists, an argument to this could, for example, be the filename of anopen()system call. This operation returns astruct inodewith attributes about this inode if it does exist. In case of a FUSE_LOOKUP request being issued, the name of the file to be looked up is stored directly after the header. The FUSE server can derive the length of the name from the length field of the header of the request - The server handles the lookup in whichever way it pleases
- a FUSE reply is sent back to the server
FUSE replies, like their request counterparts, also use a standardized header, which looks like this:
struct fuse_out_header {
uint32_t len;
int32_t error;
uint64_t unique;
};
The error field can be either 0 or any value that is a valid errno value to indicate the request failed. The unique field must contain the same identifier of the request that this reply is for and the length field again gives information about the total size of the reply.
To continue the example of a FUSE_LOOKUP request, the following structures are expected to follow the reply header:
// This is the struct following the out header in a LOOKUP reply
struct fuse_entry_out {
uint64_t nodeid; /* Inode ID */
uint64_t generation; /* Inode generation */
uint64_t entry_valid;
uint64_t attr_valid;
uint32_t entry_valid_nsec;
uint32_t attr_valid_nsec;
struct fuse_attr attr;
};
struct fuse_attr {
uint64_t ino;
uint64_t size;
uint64_t blocks;
uint64_t atime;
uint64_t mtime;
uint64_t ctime;
uint32_t atimensec;
uint32_t mtimensec;
uint32_t ctimensec;
uint32_t mode;
uint32_t nlink;
uint32_t uid;
uint32_t gid;
uint32_t rdev;
uint32_t blksize;
uint32_t padding;
};
This kind of reply struct is very interesting as it shows just how much control FUSE gives an unprivileged process over the actual data and metadata of the files it serves. The first field is an inode ID which will later be used in other requests to refer to this inode. generation is another internal identifier. This is followed by, attr_valid and entry_valid. These fields tell the FUSE driver for how many seconds this inode and its attributes should be kept in a kernel internal cache. The *_nsec counterparts of these fields do the same thing, they just work on a much finer time granularity.
Finally the struct fuse_attr follows. Readers who are familiar with Unix systems surely already recognized that this struct simply represents the metadata of an inode, such as the owner, the permissions, size, etc.
To conclude this example: Implementing a FUSE server is quite simple. All that needs to be done is check which opcode is requested and associate the request with an inode and call a handler responsible for this opcode. Then, depending on the opcode send back a FUSE reply. Since there are 49 different opcodes at the time of writing, I won’t go through how to handle all of them here. There are already better resources than I could ever write. Alternatively one could just read the contents of the fuse.h include file of libfuse, which details all the different requests and reply structs.
Fuzzing FUSE
The next section will explore the problems I faced fuzzing FUSE with Syzkaller and how I solved them one by one.
Problem #1: FUSE is a client-server architecture
When FUSE is used as intended, there is usually one process interacting with a file backed by a FUSE mount and one process interacting with the FUSE driver to respond to the replies generated by the first process.
This kind of architecture makes fuzzing FUSE complicated. The reason for this is the way inputs for Syzkaller are generated and tested.
Like any other fuzzer, Syzkaller runs in a loop. Due to its nature as a structured fuzzer, it can not only mutate existing inputs but also generate new ones. The generation is quite simple: the fuzzer chooses a random amount of syscalls and then generates randomized (but structured) arguments for these syscalls.
In the serialized form, such an input could then look like this:
open(&(0x7f0000000000)='./file0\x00', 0xbc0, 0xa09a214393baae7c)
r0 = creat(&(0x7f0000000000)='./file0\x00', 0x0)
newfstatat(0xffffffffffffff9c, &(0x7f0000000040)='./file0\x00', &(0x7f0000000100)={0x0, 0x0, 0x0, 0x0, <r1=>0x0}, 0x0)
setuid(r1)
write$cgroup_type(r0, &(0x7f00000020c0)='threaded\x00', 0x9)
Alternatively, when Syzkaller chooses to mutate an input, it can remove or insert system calls, splice the “program” with another program from the corpus or simply mutate an argument. Here is part of the corresponding code of this logic:
for stop, ok := false, false; !stop; stop = ok && len(p.Calls) != 0 && r.oneOf(3) {
switch {
case r.oneOf(10):
// Not all calls have anything squashable,
// so this has lower priority in reality.
ok = ctx.squashAny()
case r.nOutOf(1, 100):
ok = ctx.splice()
case r.nOutOf(20, 31):
ok = ctx.insertCall()
case r.nOutOf(10, 11):
ok = ctx.mutateArg()
default:
ok = ctx.removeCall()
}
}
Now once Syzkaller has finished generating or mutating an input, it will execute the syscalls one by one in the order they were generated. (This is not entirely true, but we don’t need to get into more detail here). Such a flow works fine for most syscalls, but not for file-system operations when fuzzing FUSE.
Let’s say for example one of the generated system calls is a lseek() on a FUSE file. The process that made this system call will have to wait until the FUSE server has replied to the generated FUSE_SEEK request. However, since there is no server being able to handle this request the system call will simply time out and hang the execution of the input.
Using ‘syzcalls’ to solve this problem
If you are unfamiliar with Syzlang, please read up on it on the Documentation page. It is an amazing feature of Syzkaller and very easy to understand.
A neat feature of Syzkaller is to allow defining syzcalls. These syzcalls have the same syntax as normal syscalls in the Syslang with the difference that they are functions that will be called in user-space within the fuzzer process.
To make this concept a little more feasible, take the following example ‘syzkall’ description and the corresponding implementation:
syz_example(int64 ex_arg)
int syz_example(int64_t ex_arg) {
// do some magic
}
With this feature, it is possible to write wrappers around system calls. Let’s say for example I wanted to support the open() file-operation for FUSE. I could write a syzkall like the following:
syz_open_file_fuse(fuse_replies ptr[in, array[fuse_replies_structs]], fuse_opcodes ptr[in, array[const[0, int64]]], fuse_num_replies len[fuse_opcodes], file ptr[in, string] oflags flags[open_flags], mode flags[open_mode], fd fd_fuse) fh_fuse
We will go into more depth as to why I chose to define this wrapper as it is and what the arguments actually mean, but for now all you need to roughly know about the arguments of this syzkall definition:
- fuse_replies: This is a pointer to an array of generated FUSE replies
- fuse_opcode: This is a pointer to an array of 64bit values that map to the array of generated FUSE replies
- fuse_num_replies: The number of FUSE replies and opcodes.
- fd_fuse: A file descriptor to the /dev/fuse char device.
- fh_fuse return resource: A file descriptor to a logical FUSE file
The other arguments are specific to open() and are the filename, open flags, and creation mode.
The purpose of the syz_open_file_fuse() wrapper is to take the following steps:
fork()and create a child process- The child process will call
open()with the randomized arguments - The parent process will read from /dev/fuse and reply with the appropriate generated FUSE reply
Let’s go through some of my code! I won’t be able to cover everything in this blog post, but I did upload the entirety of the code to this GitHub repo so you can just take a look at it yourself. The code we are currently looking at is located in common_linux.h.
static int syz_open_file_fuse(
struct fuse_out_header *fuse_replies,
uint64_t fuse_opcodes[],
size_t fuse_num_replies,
uint64_t open_flags,
uint64_t mode,
int fd_fuse)
{
if(fd_fuse == -1 || !fuse_initialized) {
return -1;
}
open_args.oflags = open_flags;
open_args.mode = mode;
// We need to clone() for the open call so that we can actually respond to the request
// the child process will write the resulting FD into file_fd
int pipefd = fuse_helper_clone_func(clone_file_open, NULL);
if (pipefd == -1) {
return -1;
}
int retval = fuse_helper_handle_call(fd_fuse, pipefd, fuse_replies, fuse_opcodes, fuse_num_replies, buffer);
// add this program to the opened files so that we can forcefully close them later!
if (retval != -1) {
fuse_opened_files[fuse_num_opened_files++] = retval;
successful_open++;
} else {
failed_open++;
}
return retval;
}
The first thing you will notice is the function prototype of syz_fuse_open_file_fuse() and how it implements the corresponding syzkall. We then check if the FUSE FD is invalid or if FUSE has not been initialized yet. FUSE initialization is simply a FUSE reply for the opcode FUSE_INIT, which is requested after mounting FUSE. The reason for this check is so we can avoid making expensive fork() operations if there is no point in it anyways.
The code then copies the arguments for the open call to the global variable open_args (ugly I know, but I had my reasons).
Finally, the fuse_helper_clone_func() is called and passed a callback.
This helper function calls fork() and then creates a pipe between the parent and child process to enable them to exchange for example the return value of the system call and other information. It will then call the function it was passed to as an argument. In this case, it is clone_file_open() , which will simply call open() with the randomized arguments.
Following is a call to fuse_helper_handle_call() , which simply reads and writes to the /dev/fuse device to process FUSE requests.
The reason I wrapped the logic of my solution (essentially just fork() into a client-server) is to enable easy implementation of other file operations.
Problem #2: Different inputs to FUSE operations require different FUSE replies
When I first approached writing the system call descriptions for fuzzing FUSE, I thought I could simply write a descriptor for let’s say open() and define one of the arguments as a FUSE reply for the FUSE_OPEN opcode. Now, I mentioned earlier that before an open() can occur, the kernel must first verify that the inode the open() should be performed on even exists. To do this, it will perform a lookup which will result in a FUSE_LOOKUP request.
However, it gets even more complicated than that. What if the file that should be open()‘ed is multiple directory levels deep? This would mean a FUSE_LOOKUP request would be generated for every directory in the path to be opened. Now, what if the mutator decides to flip some bits in the file mode bits for one of the inodes in the path, which results in part of the path being interpreted as a symlink? In this case a FUSE_READLINK request would be generated.
There are special cases like this for a lot of the FUSE operations. Another example would be writing to a page of a mmap()‘d FUSE file. In that case, a FUSE_WRITE or FUSE_FSYNC request could be issued at any time.
The point is, simply mapping a FUSE reply struct to a file operation is not enough and a generic way of creating and mutating correct FUSE replies must exist.
In order to understand the solution for this problem better, let’s have a look at this wonderful graph describing Syzkaller’s architecture, which I borrowed from their GitHub page:
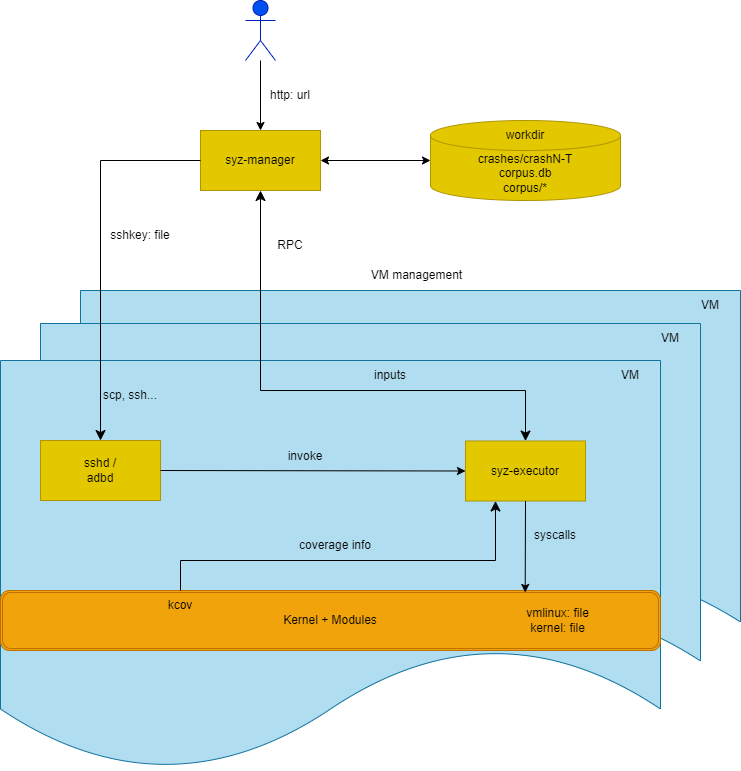
For the sake of solving this problem, the interaction between the syz-fuzzer, syz-executor and kernel is the most interesting thing in this graphic. Within each VM started by Syzkaller, there is one process generating the inputs and another actually executing them. One major reason to separate those processes would be the risk that the kernel could overwrite arbitrary memory locations within the user-space process making the system calls, which could lead to all sorts of problems including loss of coverage, corpus corruption, and most likely the fuzzer crashing and having to be restarted, which takes some time.
It is not obvious when looking at the graphic, but the syz-fuzzer and syz-executor processes are communicating through pipes. The fuzzer sends some information about the current fuzz case, for example, if it is a debug fuzz case or if a fault injection should occur, and if so when, etc. The executor then sends back collected coverage information, as well as return values and other meta-information about the system calls executed.
My approach to solving the problem of FUSE handlers requiring unpredictable, structured data was to simply add another pipe which enables the executor to ask the fuzzer for a generated FUSE reply for a specific opcode. Let’s look at the code of the handle_fuse_request() helper function I wrote:
int handle_fuse_request(int fuse_fd, struct fuse_out_header *fuse_replies, uint64_t opcodes[], size_t fuse_num_replies, int requests_received, struct fuse_in_header *req)
{
errno = 0;
int err = read(fuse_fd, buf, FUSE_IN_BUFSIZE);
if (err < 0) {
return err;
}
// no reply needed for FUSE_FORGET
if (req->opcode == FUSE_FORGET || req->opcode == FUSE_BATCH_FORGET) {
return 0;
}
struct fuse_out_header *hdr;
// Check if we have a matching pre generated reply
if ((size_t)requests_received < fuse_num_replies && opcodes[requests_received] == buf->opcode) {
hdr = (struct fuse_out_header *)((char *)fuse_replies + (FUSE_REPLY_SIZE * requests_received));
} else if (buf->opcode == FUSE_READDIRPLUS) {
hdr = (struct fuse_out_header *)direntplus_reply;
} else if (buf->opcode == FUSE_READDIR) {
hdr = (struct fuse_out_header *)dirent_reply;
}
else {
// Otherwise request an on the fly generation
hdr = request_fuse_opcode_reply(req->opcode, requests_received, get_current_call_index());
}
req->unique = req->unique;
err = write(fuse_fd, hdr, hdr->len);
if (err < 0) {
return err;
}
return 0;
}
First of all, the arguments to the function are simply the pointer to the array of already generated FUSE replies for this call, the opcode mapping, and the number of already generated replies. The requests_received argument is just an index of how far into the array of generated replies for this operation we are.
The first step of the function is to just read() the next incoming FUSE request from the /dev/fuse driver. It will then compare the opcode of this request to the opcode of the current generated FUSE reply. If it does, it will simply return a pointer to it. It will also handle 2 special cases for FUSE_READDIRPLUS and FUSE_READDIR which we don’t need to get into right now.
In case there is no generated FUSE reply for this request, request_fuse_opcode_reply() is called, which writes the opcode that is requested to the FUSE pipe, as well as the system call for which to generate this reply and the index within the generated FUSE replies array for this call.
The fuzzer process will then read the request for a generated FUSE reply from its end of the FUSE pipe, generate the FUSE reply struct, and add it to the already generated FUSE replies for this file operation of the input.
The last step, regardless of how a FUSE reply was obtained, is to set the correct unique identifier in the reply for this request and then write() the FUSE reply to the /dev/fuse driver.
If you are interested, feel free to read the code I wrote for the fuzzer, which handles generating FUSE replies on the fly here. This part of the code also modifies the current input to add the generated reply so that it can be re-used and mutated when the input is executed again.
Additional feature: Syzlang sequencing
One problem I kept running into when trying to fuzz a specific feature with Syzkaller was that sometimes I just wanted to fuzz a set order of system calls and then only mutate the arguments to them. For example, if I wanted to fuzz the readdir() operation of FUSE, I would simply want the following system calls in my inputs:
open()to /dev/fusemount()with the FD- initialization of FUSE through the FUSE_INIT opcode.
readdir()on a dir inside the FUSE mount
Now, I would only want these system calls to be executed without the fuzzer inserting/removing random system calls, and I would need those system calls to be executed in this particular order. I could then concentrate the fuzzing time on just mutating the arguments to those calls. Theoretically, I could just write a single syzkall wrapper where these calls are made and pass the arguments to all the different calls as arguments. This would kind of work, but the fuzzer would still insert random system calls around this wrapper.
For this reason I extended the Syzlang compiler with some additional keywords, namely sequence and group.
Here is an example of a sequence definition:
sequence FUSE_IOCTL syz_mount_fuse() fd_fuse syz_init_fuse(fd fd_fuse, reply ptr[in, fuse_out[fuse_init_out]]) syz_open_file_fuse(/* FUSE args omitted */, oflags flags[open_flags], mode flags[open_mode], fd fd_fuse) fh_fuse syz_ioctl_file_fuse(/* FUSE args omitted */, cmd int64, arg vma[0:256], file fh_fuse, fd fd_fuse) syz_close_files_fuse(/* FUSE args omitted */, fd fd_fuse) syz_unmount_fuse(fd fd_fuse) endsequence
This creates a sequenced program. Such a program is still treated like any other input and can be moved into the corpus. The only difference to a normal input is that in such a sequenced program, only the arguments are mutated to save time. Another advantage of such an approach is that scenarios, where one system call hangs without the presence of another, can be avoided and thus the number of timeouts can be reduced and performance increased.
Now, to make this feature more flexible, I added the ability to add system calls to groups. The syntax is almost the same, as it is to add system calls to a sequence. Here is an example of a group definition:
group ABC_GROUP syscall_a() syscall_b() syscall_c() endgroup
A group can be used in two ways:
- Tell the mutator that these system calls are somehow logically related and should be combined more frequently into an input than unrelated system calls
- Add certain system calls dynamically to sequences
The first use-case will be discussed in another blog post as it addresses an entirely different problem, namely corpus management.
As for the second use-case, let’s take a look at an example definition of a sequence using groups:
sequence FUSE1 syz_mount_fuse() fd_fuse syz_init_fuse(fd fd_fuse, reply ptr[in, fuse_out[fuse_init_out]]) syz_open_file_fuse(/* FUSE args omitted */, oflags flags[open_flags], mode flags[open_mode], fd fd_fuse) fh_fuse groups FUSE_FILE_OPS_FH syz_close_files_fuse(/* FUSE args omitted */, fd fd_fuse) syz_unmount_fuse(fd fd_fuse) endsequence
This is actually one of the sequences I used for fuzzing FUSE. It reads as follows:
syz_mount_fuse(). This will internally open /dev/fuse and return the FD as a resource- initialize FUSE trough
syz_init_fuse()and a FUSE_INIT reply - open a FUSE file within the mount
- At this point in the program, insert / remove / mutate any number of calls belonging to the
FUSE_FILE_OPS_FHgroup - close opened FUSE files
- unmount FUSE
Conclusion
I mentioned in the introduction of the blog post that Google already had a solution for fuzzing FUSE. I mentioned that comparing these changes to their solution is not entirely fair, as Google is concerned with fuzzing the entirety of a kernel and not just FUSE. Therefore, their solution is much less performant than the final product of the solutions I talked about in this blog post.
However, I want to note that in the conversation of the pull request for the FUSE support of Syzkaller, Dmitry Vyukov, one of the team leaders of Syzkaller, stated that after 20 hours of fuzzing, 61% of coverage for fs/fuse/readdir.c was achieved. The fuzzer described here achieves more coverage in less than an hour on 6 cores on a gaming PC:

This does not necessarily say anything about Google’s solution as I do not know the hardware Dmitry used for his test run, as well as the parameters for the run. I just want to point out that this fuzzer does what it is supposed to do: Fuzz FUSE specifically effectively.

